
rok budowy na podstawie współrzędnych geo
W poprzednim wpisie (jak-wytresowac-smoka-kategoryzacja-tekstu-czyli-standard-wykonczenia-na-podstawie-opisow-w-ogloszeniach) zaprezentowaliśmy metodę na określenie standardu wykończenia lokalu na podstawie opisu zawartego w ofercie sprzedaży nieruchomości, za pomocą sieci neuronowej trenowanej na stokenizowanym opisie.
Poza niezdefiniowanym standardem wykończenia, część ofert nie zawiera także podanego roku budowy budynku. Pokażemy w niniejszym wpisie sposób na uzupełnienie tych brakujących wartości.
Wczytujemy plik z przypisanymi już wartościami dla standardu, tworzymy z niego DataFrame oraz kasujemy kolumnę ‘tokens’, która jest już nam nie potrzebna (używaliśmy ją do predykcji standardu wykończenia):
df = np.load("dane_ALL_po_predykcji_standardu.npy",allow_pickle=True)
df= pd.DataFrame(df,columns = ["cena1m2", "pow", "rok_budowy","kond","l_kond","geo_lat","geo_lng","stan","kategoria","opis","tokens","prediction_standard"])
df = df.drop("tokens", axis=1)
Przekształcamy wartości kolumn ‘geo_lat’, ‘geo_lng’, ‘rok_budowy’ na wartości liczbowe:
df['geo_lng']=pd.to_numeric(df['geo_lng'])
df['geo_lat']=pd.to_numeric(df['geo_lat'])
df['rok_budowy']=pd.to_numeric(df['rok_budowy'])
Ograniczmy nasz zbiór do nieruchomości znajdujących się w Warszawie (mniej więcej) – w zbiorze “zaplątało” się kilka nieruchomości oznaczonych prawdopodobnie błędnymi współrzędnymi, które zaciemniałyby nam wykresy):
df = df[(df['geo_lat'] >= 52) & (df['geo_lat'] <= 52.5)]
df = df[(df['geo_lng'] >= 20.8) & (df['geo_lng'] <= 21.4)]
Rysujemy wykres zgodnie ze współrzędnymi geo, kolorem oznaczamy rok budowy, krzyżykiem oznaczamy ofertę gdzie nie podano roku budowy:
import matplotlib.cm as cm
import matplotlib.colors as colors
x=df['geo_lng']
y=df['geo_lat']
z=df['rok_budowy']
cmap = cm.get_cmap("viridis")
mask = ~np.isnan(z)
min_z = np.nanmin(z[mask])
max_z = np.nanmax(z[mask])
normalize = colors.Normalize(vmin=min_z, vmax=max_z)
colors_valid = cmap(normalize(z[mask]))
plt.scatter(x[mask], y[mask], alpha=0.2, c=colors_valid)
plt.scatter(x[~mask], y[~mask], alpha=0.8,color='black', marker='x', label='NaN')
plt.xlabel('geo_lng')
plt.ylabel('geo_lat')
cb = plt.colorbar(cm.ScalarMappable(cmap=cmap, norm=normalize),label='rok budowy')
plt.legend()
plt.show()

w powiększeniu:
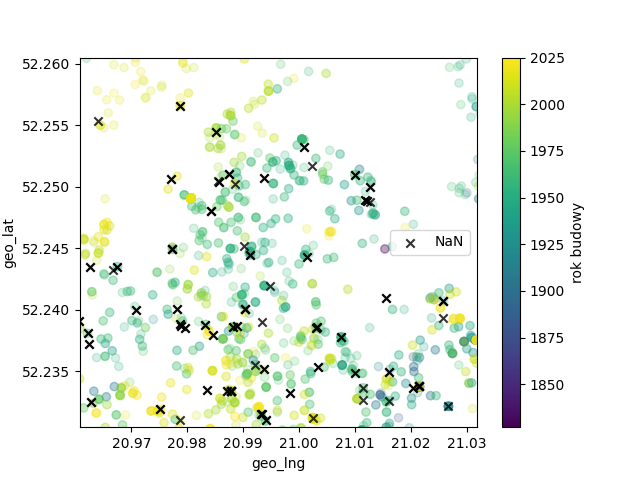
Ofert bez podanego roku budowy jest dość dużo (ok. 850), więc warto je uzupełnić (pozostawienie nieuzupełnionych danych uniemożliwiłoby nam dalszą pracę nad zbiorem, a odrzucenie tak dużej ilości danych też nie jest dobrym pomysłem).
Uzupełnimy brakujące wartości za pomocą algorytmu KNeighborsClassifier.
KNeighborsClassifier to algorytm klasyfikacji oparty na najbliższych sąsiadach. W skrócie polega na tym, że dla każdego nowego przypadku, algorytm szuka k najbliższych przypadków z już znanymi etykietami w zbiorze treningowym i przypisuje nowemu przypadkowi etykietę, która jest najczęściej występującą wśród jego k najbliższych sąsiadów. Wartość k jest parametrem algorytmu i można ją ustawić (zastosujemy wartość 3, czyli rok budowy będzie ustalany na podstawie roku budowy trzech najbliższych sąsiadów).
from sklearn.neighbors import KNeighborsClassifier
# Stworzenie maski określającej, które wartości są brakujące
not_nan_index = ~df['rok_budowy'].isnull()
# Stworzenie modelu KNeighborsClassifier
neigh = KNeighborsClassifier(n_neighbors=3)
# Trenowanie modelu na wierszach zawierających wartość roku budowy
neigh.fit(df.loc[not_nan_index, ['geo_lng', 'geo_lat']], df.loc[not_nan_index, 'rok_budowy'])
# Wypełnianie brakujących wartości
df.loc[~not_nan_index, 'rok_budowy'] = neigh.predict(df.loc[~not_nan_index, ['geo_lng', 'geo_lat']])
Rysujemy wykres na podstawie uzupełnionych danych:

Jak widać, udało nam się uzupełnić w miarę racjonalny sposób brakujące dane. Oczywiście sposobów na uzupełnianie danych jest więcej, moglibyśmy użyć innego algorytmu, czy chociażby uzupełnić te wartości średnią z całej kolumny.
http://www.adamczyk-wyceny.pl/jak-wytresowac-smoka-czyli-sieci-neuronowe-w-praktyce/