
standard wykończenia na podstawie opisów w ogłoszeniach
Kategoryzacja tekstu to proces polegający na przypisaniu danego tekstu do jednej lub wielu kategorii. Jest to ważne zagadnienie w przetwarzaniu języka naturalnego, ponieważ pozwala na automatyzację procesów, takich jak klasyfikacja wiadomości e-mail czy wyszukiwanie informacji.
Sieci neuronowe są jednym z najpopularniejszych sposobów na rozwiązanie problemu kategoryzacji tekstu. Dzieje się tak dlatego, że sieci neuronowe posiadają zdolność uczenia się na podstawie przykładów oraz mogą radzić sobie z dużą ilością danych.
Do kategoryzacji tekstu wykorzystuje się różne rodzaje sieci neuronowych, takie jak sieci neuronowe konwolucyjne (CNN), sieci neuronowe rekurencyjne (RNN) czy sieci transformers. Każdy z tych modeli ma swoje własne zalety i jest odpowiedni do rozwiązania specyficznych problemów.
Przed trenowaniem sieci neuronowej potrzebne jest przygotowanie danych. Zazwyczaj dane tekstowe przedstawia się w postaci wektorów numerycznych, które są następnie używane jako wejście do sieci neuronowej. Dla tego procesu wykorzystuje się zazwyczaj techniki kodowania one-hot lub word2vec.
W procesie uczenia sieć neuronowa analizuje przykłady tekstu i ich etykiety kategoryczne, ucząc się związku między nimi. Po uczeniu model jest w stanie przypisywać kategorię dla nowego, nieznanego mu dotąd tekstu.
(https://openai.com/blog/chatgpt/)
W niniejszym wpisie użyjemy zbioru ofert sprzedaży lokali mieszkalnych zamieszczonych na jednym z portali ogłoszeniowych.
W celu ograniczenia wpisu nie przedstawimy całego kodu programu, jedynie jego istotniejsze założenia.
Zbiór nasz (nazwijmy go zbiorem OFERT) składa się z 12163 ogłoszeń.
Każde ogłoszenie składa się m.in. z:
- współrzędnych geograficznych
- ceny lokalu
- powierzchni lokalu
- kondygnacji na której znajduje się lokal
- liczby kondygnacji budynku
- roku budowy budynku
- opisu standardu wykończenia (jeżeli nie był podany – pole pozostaje puste)
- opisu oferty
Przykładowy “opis oferty” wygląda tak:
“Do sprzedania dwupokojowe mieszkanie z oddzielną kuchnią, łazienką i piwnicą. Mieszkanie na piątym piętrze w budynku z 1955 roku, dwustronne w pełni rozkładowe z widokiem na park i zachodnią panoramę Warszawy oraz podwórko. Budynek pięciopiętrowy z windą, nad mieszkaniem jest jeszcze przestrzeń (rodzaj poddasza). Mieszkanie do remontu. Klatka schodowa czysta, wyremontowana. Mieszkanie z Księgą Wieczystą, własność gruntu. Ciche spokojne osiedle w sercu(…)”
Opis standardu wykończenia jest krótkim tekstem typu: “WYSOKI STANDARD”, “W BUDOWIE”, “DO DROBNEGO REMONTU” itp.
Do wyuczenia modelu, aby przewidywał nam standard wykończenia lokalu na podstawie “opisu oferty”, wykorzystamy dane ze zbioru OFERT z kolumny “opis oferty” oraz kolumny “standard wykończenia”.
Tworzymy w tabeli OFERT nową kolumnę “kategorie” i przypisujemy jej wartości:
0 – dla standardu “deweloperskiego”
1 – dla standardu niskiego
2 – dla standardu średniego
3 – dla standardu dobrego
Wartości te przypisujemy na podstawie opisu standardu wykończenia, zgodnie z kodem:
standard_low_dev=['DEWELOPERSKI','BEZ BIAŁEGO MONTAŻU I PODŁÓG', 'DEVELOPERSKI', 'STAN DEWELOPERSKI', 'W BUDOWIE', 'NOWE DO WYKOŃCZENIA']
standard_low=['DO REMONTU','DO WYKOŃCZENIA','DO REMONTU KAPIT.', 'DO REMONTU KAPITALNEGO', 'DO KAPITALNEGO REMONTU', 'DO REMONTU GENERALNEGO', 'DO GENERALNEGO REMONTU', 'WYMAGA REMONTU KAPITALNEGO']
standard_middle=['DO ODŚWIEŻENIA','DO MALOWANIA','CZĘŚCIOWO PO REMONCIE','DO ADAPTACJI','DO ODNOWIENIA', 'WYMAGA DOPASOWANIA', 'DO REMONTU DROBNEGO', 'DO CZĘŚCIOWEGO REMONTU','DO DROBNEGO REMONTU']
standard_good=['WYSOKI STANDARD','BARDZO DOBRY','BARDZO WYSOKI STANDARD','DO ZAMIESZKANIA','DO WPROWADZENIA','PO GENERALNYM REMONCIE', 'PODWYŻSZONY', 'IDEALNY', 'WYKOŃCZONY','WYSOKI','LUKSUSOWY','NOWE','NOWY']
Otrzymaliśmy podzbiór zbioru OFERT (nie wszystkie ogłoszenia miały podany opis standardu wykończenia) zawierający kolumny “opis oferty”, “standard wykończenia” oraz “kategorie” czyli standard wykończenia opisany liczbami 0,1,2,3. Nasz podzbiór liczy ok. 5000 elementów (ok. 3000 lokali w standardzie “dobrym”, .ok. 900 w standardzie “średnim” i po ok. 300-400 w standardzie “deweloperskim” i “średnim”).
Histogram z podziałem na przypisane “kategorie” przedstawiony jest poniżej:
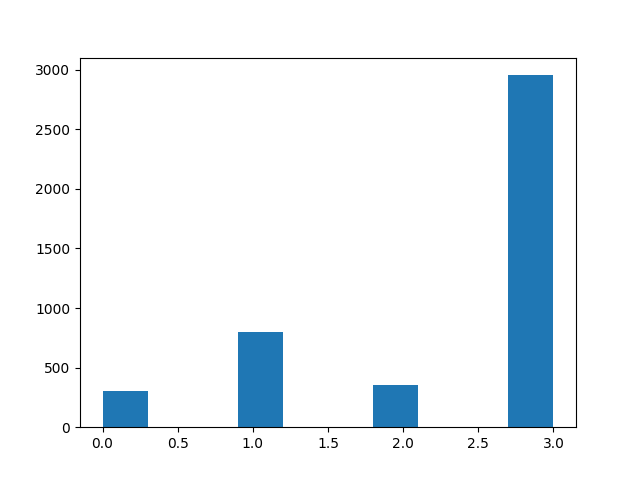
Jak widzimy najwięcej mamy ofert w standardzie dobrym (‘3’), najmniej w standardzie deweloperskim (‘0’) oraz średnim (‘2’).
Przekształcamy następnie kategorie na “gorąco jedynkowe” (ang. one-hot encoding).
W następnym etapie dokonamy wstępnego przetworzenia tekstu z kolumny “opis ofert”. Przetworzenie to z reguły polega na tokenizacji tekstu oraz jego standaryzacji itp. Dla uproszczenia posłużymy się gotowym modelem opracowanym (wyuczonym) przez google a udostępnionym na stronie https://tfhub.dev/google/universal-sentence-encoder-multilingual/3. Model ten przekształca tekst na wektor 512 elementowy (jest to wektor 512 cech tekstu). Wynikowy wektor może być użyty do uczenia naszego modelu.
Zdefiniujmy nasz model:
model=tf.keras.models.Sequential()
model.add(tf.keras.layers.Input(shape=[512]))
model.add(tf.keras.layers.Reshape(target_shape=[512, 1]))
model.add(tf.keras.layers.Conv1D(filters=512, kernel_size=3, activation='relu'))
model.add(tf.keras.layers.Conv1D(filters=512, kernel_size=3, activation='relu'))
model.add(tf.keras.layers.MaxPooling1D())
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dropout(rate=0.25))
model.add(tf.keras.layers.Dense(128, activation="relu"))
model.add(tf.keras.layers.Dropout(rate=0.25))
model.add(tf.keras.layers.Dense(64, activation="relu"))
model.add(tf.keras.layers.Dropout(rate=0.25))
model.add(tf.keras.layers.Dense(4, activation="softmax"))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=["accuracy"])
Nasz model składa się m.in. z warstwy wejściowej (gdzie podawany jest wektor 512 elementowy który otrzymaliśmy po przekształceniu tekstu z kolumny “opis oferty” przez ww. model universal-sentence-encoder-multilingual), 2 warstw splotowych, warstwy MaxPooling, warstwy spłaszczającej oraz szeregu warstw Dropout oraz Dense. Wyjściowa warstwa składa się z 4 elementów z funkcją aktywacji “softmax” i na wyjściu podaje prawdopodobieństwa przynależności opisu oferty do jednej z czterech klas (0,1,2 lub 3 czyli standardu “deweloperskiego”, “niskiego”, “średniego” lub “dobrego”).
Trenujemy nasz model:
model.fit(inputs,target, epochs=15,validation_split = 0.05)
wykresy “loss” i “accuracy” z procesu uczenia:


jak widać na powyższych wykresach, model jest lekko przetrenowany, uczenie można było zakończyć na mniej więcej 10 epokach.
Model całkiem dobrze potrafił przypisać “opis oferty” do kategorii standard wykończenia (0,1,2 i 3) na zbiorze testowym. Pomylił się jedynie 5 razy (niebieskie kółka nie zakryte czerwonym krzyżykiem):
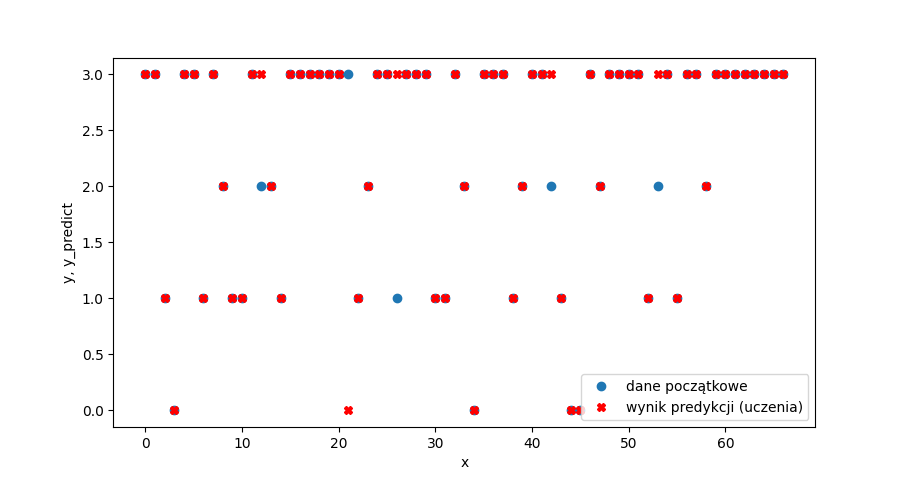
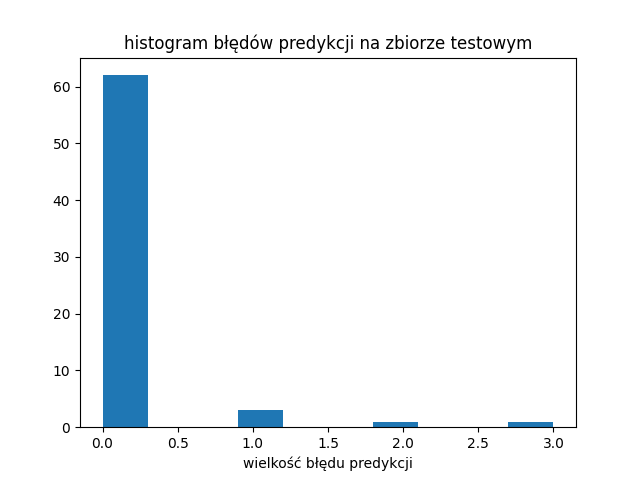
Wyuczonego modelu można teraz użyć do przypisania kategorii standard wykończenia (0-“deweloperski”, 1 – “niski”, 2 – “średni”, 3 – “dobry”) dla pozostałej części zbioru OFERT która nie miała podanego (przez sprzedającego) opisu standardu wykończenia.
http://www.adamczyk-wyceny.pl/jak-wytresowac-smoka-czyli-sieci-neuronowe-w-praktyce/