
W poprzednim wpisie (tutaj) otrzymaliśmy zbiór ofert nieruchomości z uzupełnionymi danymi dotyczącymi roku budowy. Dziś pokażemy jak podzielić zbiór ze względu na lokalizację.
Do podzialu danych ze względu na lokalizację możemy użyć algorytmu KMeans z biblioteki Scikit-learn (sklearn).
KMeans jest to algorytm klasteryzacji (grupowania), który jest używany do grupowania podobnych obiektów w grupy (klastery). KMeans jest to algorytm iteracyjny, który zatrzymuje się, gdy centroidy nie ulegną już zmianie. Każdy obiekt jest przypisywany do jednej i tylko jednej grupy. W rezultacie otrzymujemy kilka grup obiektów, które są podobne do siebie. Szczegóły dostępne są np. na Wikipedi.
Na potrzeby obliczeń definiujemy funkcję:
def kmeans_geo(df,n_clusters):
# tworzenie modelu k-średnich
kmeans = KMeans(n_clusters=n_clusters)
# dostosowywanie modelu do danych
kmeans.fit(df[['geo_lat', 'geo_lng']])
# dodawanie etykiet klastrów do oryginalnego DataFrame
df['cluster_kmeans'] = kmeans.labels_
return 'cluster_kmeans'
Wczytujemy także granice dzielnic z przygotowanego wcześniej pliku geojson, sprawdzamy w jakich dzielnicach znajdują się nasze nieruchomości oraz tworzymy dodatkową kolumnę ‘dzielnica’ do ktorej przypisujemy wartość kolumny z pliku geojson ‘NAZWAJEDNO’ która została przypisana do naszej nieruchomości i która odpowiada dzielnicy w której znajduje się nieruchomość:
city_borders = gpd.read_file("granice_miast.geojson")
gdf = gpd.GeoDataFrame(df, geometry=gpd.points_from_xy(df['geo_lng'], df['geo_lat']))
# sprawdzanie, które punkty znajdują się w granicach dzielnic
result = gpd.sjoin(gdf, city_borders, op='within')
df=result
df['dzielnica']=df['NAZWAJEDNO']
df=df[['cena1m2', 'pow', 'rok_budowy','kond','l_kond','geo_lat','geo_lng','prediction_standard','dzielnica']]
Definiujemy funkcję rysującą wykres z podziałem lokalizacji nieruchomości na klastry oraz z granicami dzielnic:
def plot_map(df,city_borders,cluster_area):
x=df['geo_lng']
y=df['geo_lat']
codes, uniques= pd.factorize(df[cluster_area].apply(str))
df[cluster_area]=codes
z=df[cluster_area]
delta_geo=0.02
x_min, x_max = (x.min()-delta_geo), (x.max()+delta_geo)
y_min, y_max = (y.min()-delta_geo), (y.max()+delta_geo)
plt.gca().set_xlim([x_min, x_max])
plt.gca().set_ylim([y_min, y_max])
city_borders.plot(ax=plt.gca(), edgecolor='black', facecolor='white', zorder=1)
cmap = cm.get_cmap('tab20c')
min_z = np.min(z)
max_z = np.max(z)
normalize = colors.Normalize(vmin=min_z, vmax=max_z)
colors_valid = cmap(normalize(z))
plt.scatter(x, y, alpha=0.8, c=colors_valid)
plt.xlabel('geo_lng')
plt.ylabel('geo_lat')
clusters = df[cluster_area].unique()
for i, cluster in enumerate(clusters):
x_mean = df[df[cluster_area] == cluster]['geo_lng'].mean()
y_mean = df[df[cluster_area] == cluster]['geo_lat'].mean()
plt.annotate(uniques[i], (x_mean, y_mean))
plt.show()
Wywołujemy funkcję plot_map z podziałem za pomocą algorytmu KMeans na 18 klastrów (mamy 18 dzielnic w Warszawie):
plot_map(df,city_borders,cluster_area=kmeans_geo(df,n_clusters=18))
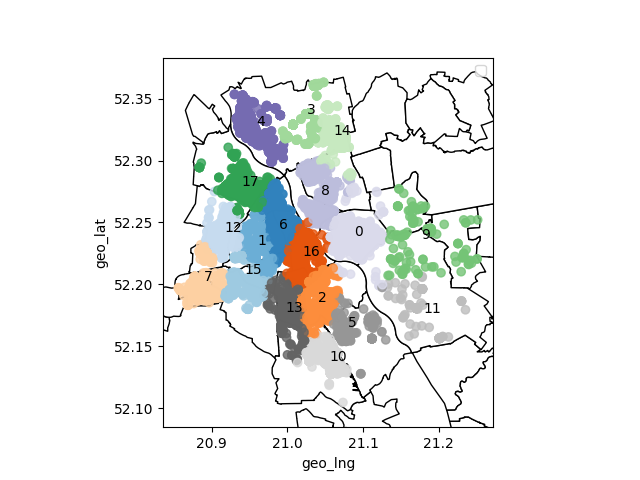
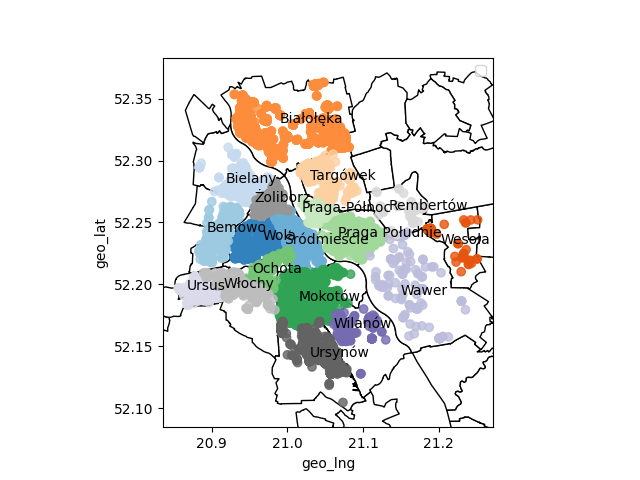
Jak widać, algorytm podzielił nam dane na obszary zaledwie zbliżone do obszarów dzielnic (co i tak wydaje się być sukcesem). Nie jest to podział zadowalający i zastosowanie go wymagałoby dobrego uzasadnienia. Jeżeli wolimy tradycyjny podział, możemy przeprowadzić podział ze względu na położenie w dzielnicach:
plot_map(df,city_borders,cluster_area='dzielnica')
Wykonajmy teraz algorytm KMeans dla jednej z dzielnic (podzielimy nieruchomości z jednej z dzielnic na 3 podzbiory, które zróźnicują nam lokalizacyjnie dzielnicę). Zrobimy to na przykładzie dzielnicy Ursus:
allowed_values = ['Ursus']
df = df[df['dzielnica'].isin(allowed_values)]
plot_map(df,city_borders,cluster_area=kmeans_geo(df,n_clusters=3))
otrzymaliśmy wykres:
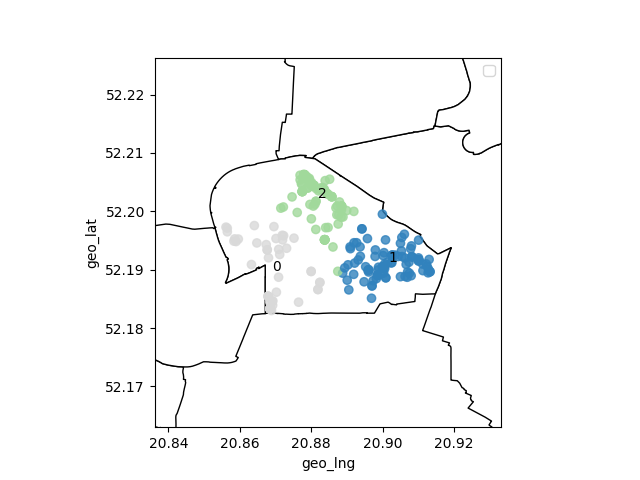
Jak widać algorytm podzielił dane na 3 obszary w sposób całkiem logiczny. Możemy oczywiście dzielić obszary na dowolną ilość klastrów w zależności od specyfiki lokalnego rynku.
- http://www.adamczyk-wyceny.pl/jak-wytresowac-smoka-rok-budowy-na-podstawie-wspolrzednych-geo/
- http://www.adamczyk-wyceny.pl/jak-wytresowac-smoka-kategoryzacja-tekstu-czyli-standard-wykonczenia-na-podstawie-opisow-w-ogloszeniach/
- http://www.adamczyk-wyceny.pl/jak-wytresowac-smoka-czyli-sieci-neuronowe-w-praktyce/