
czyli parki i przedszkola
W poprzednim wpisie pokazaliśmy, jak można podzielić nasz zbiór nieruchomości ze względu na lokalizację. Dzisiaj postaramy się zróżnicować cechę lokalizacji ze względu na odległość od parku oraz od przedszkola.
Dane dotyczące lokalizacji przedszkoli możemy pobrać ze strony: https://rspo.gov.pl/.
Musimy jedynie pozyskać dane geograficzne adresów przedszkoli, co nie stanowi dużego problemu:
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent='myGeocoder')
df['location'] = df['Adres'].apply(geolocator.geocode)
df['lat'] = df['location'].apply(lambda loc: loc.latitude if loc else None)
df['long'] = df['location'].apply(lambda loc: loc.longitude if loc else None)
Dane dotyczące parków pobieramy z geoportalu (są na tej samej warstwie co ulice). Dane te zawierają współrzędne geograficzne parków (jako ‘Polygon’).
Następnie obliczamy odległości każdej naszej nieruchomości od najbliższego parku (oczywiście jest to skrót całego kodu):
from shapely.ops import nearest_points
gdf_parks['nearest_geometry'] = gdf_parks.apply(lambda row: nearest_points(row.geometry, df['geometry'].unary_union)[1], axis=1)
df['nearest_geometry'] = df.apply(lambda row: nearest_points(row.geometry, gdf_parks['geometry'].unary_union)[1], axis=1)
for i, row in df.iterrows():
distance_park = row['geometry'].distance(row['nearest_geometry'])
row['dist_park'] = distance_park
oraz najbliższego przedszkola:
df['closest_point'] = df['geometry'].apply(lambda x: gdf_kinder['geometry'].distance(x).idxmin())
df['dist_kindergarten'] = df.apply(lambda row: distance(lonlat(row['geometry'].y, row['geometry'].x), lonlat(gdf_kinder.loc[row['closest_point'], 'geometry'].y, gdf_kinder.loc[row['closest_point'], 'geometry'].x)).m, axis=1)
Mamy teraz dla każdej nieruchomości dwie dodatkowe odległości od najbliższego parku (df[‘dist_park’]) oraz od najbliższego przedszkola (df[‘dist_kindergarten’]).
Nadajemy teraz naszym nieruchomościom cechy 1,2 lub 3:
- 3 – jeżeli odległość od parku < 300m oraz odległość od przedszkola < 500m,
- 2 – jeżeli odległość od parku < 300m oraz odległość od przedszkola >= 500m,
- 1 – w pozostalych przypadkach)
for index, row in df.iterrows():
if row['dist_park'] < 300:
if row['dist_kindergarten'] < 500:
df.loc[index, 'localization_by_distance'] = 3
else:
df.loc[index, 'localization_by_distance'] = 2
else:
df.loc[index, 'localization_by_distance'] = 1
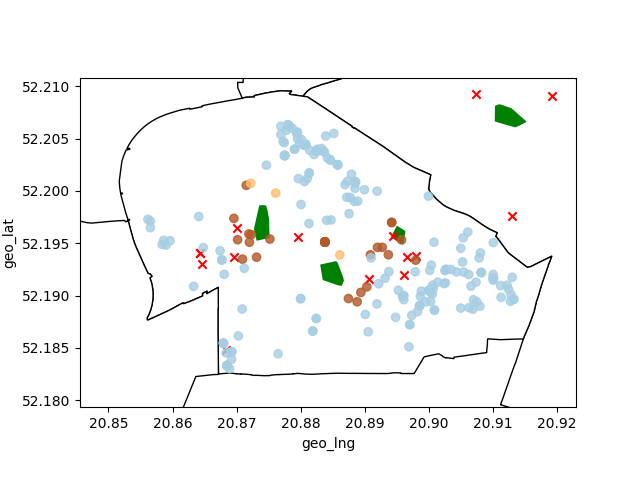
Ograniczmy dane do dzielnicy Ursus.
Rysujemy wykres z danymi (nasze nieruchomości – lokalizacja ‘1’ : kolor niebieski, lokalizacja ‘2’ : kolor beżowy, lokalizacja ‘3’ : kolor brązowy), lokalizacją parków (kolor zielony) oraz przedszkoli (czerwone krzyżyki):
Możemy narysować teraz mapę korelacji:
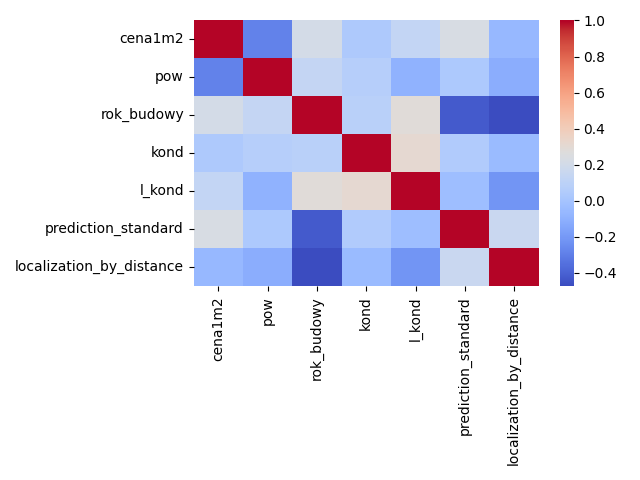
Jak widzimy, najsilniej skorelowana z ceną 1m2 jest powierzchnia (korelacja ujemna), standard (korelacja dodatnia) oraz rok budowy (korelacja dodatnia) – co wydaje się logicznie uzasadnione. Cecha lokalizacja skorelowana jest ujemnie – co świadczyć może o nieprawidłowo dobranym kryterium dla zróżnicowania cechy lokalizacji.
W powyższy sposób można oczywiście określać inne kryteria dla lokalizacji, np. odległość od stacji metra, położenie przy głównych arteriach itp.
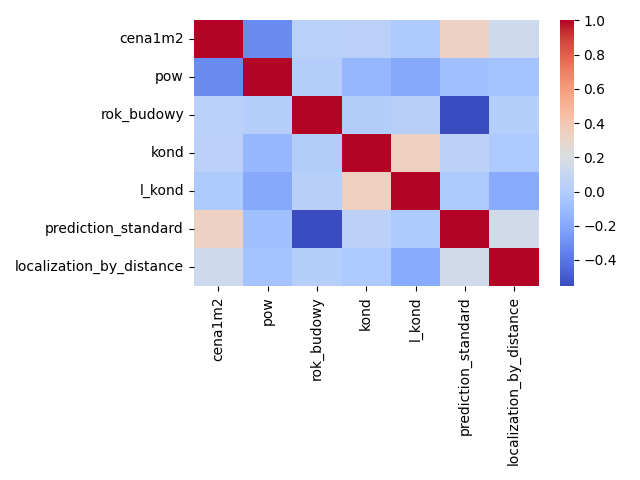
EDIT: korelacje pokazane powyżej, mogą być troche mylące ze względu na dośc szeroki rynek. Ograniczmy zatem nieruchomości:
df=df[df['rok_budowy']>1995]
df=df[df['pow']<70]
otrzymujemy mapę korelacji:
- http://www.adamczyk-wyceny.pl/jak-wytresowac-smoka-4-lokalizacja/
- http://www.adamczyk-wyceny.pl/jak-wytresowac-smoka-rok-budowy-na-podstawie-wspolrzednych-geo/
- http://www.adamczyk-wyceny.pl/jak-wytresowac-smoka-kategoryzacja-tekstu-czyli-standard-wykonczenia-na-podstawie-opisow-w-ogloszeniach/
- http://www.adamczyk-wyceny.pl/jak-wytresowac-smoka-czyli-sieci-neuronowe-w-praktyce/